


I cani robot non sono una novità: da quelli che si cimentano in pratiche sportive ai più recenti che controllano il rispetto del distanziamento sociale. A prescindere dalle caratteristiche fisiche specifiche, tutti questi robot hanno in comune una principale peculiarità: sono manovrati da remoto.
Caratteristica non riscontrabile in Jueying: creato da un team di ricercatori dell’Università cinese di Zhejiang insieme all’Università di Edimburgo, il cane robot riesce a muoversi nello spazio e a rispondere a determinati stimoli semplicemente perché ha imparato a farlo.
Immaginiamo un bambino che impara a camminare quando più piccolo. Una volta chiesto al bambino di compiere dei movimenti specifici, come salire le scale o sedersi, non si procede a dare istruzione sul come muovere una gamba o un braccio, passo passo. Il bambino lo imparerà semplicemente provandoci. Allo stesso modo, a Jueying non vengono fornite indicazioni su ogni possibile scenario realizzabile. Anche perché il mondo reale è un continuo imprevisto: difficilmente sarebbe possibile codificare ogni situazione, ogni comportamento, ogni reazione ad uno stimolo.
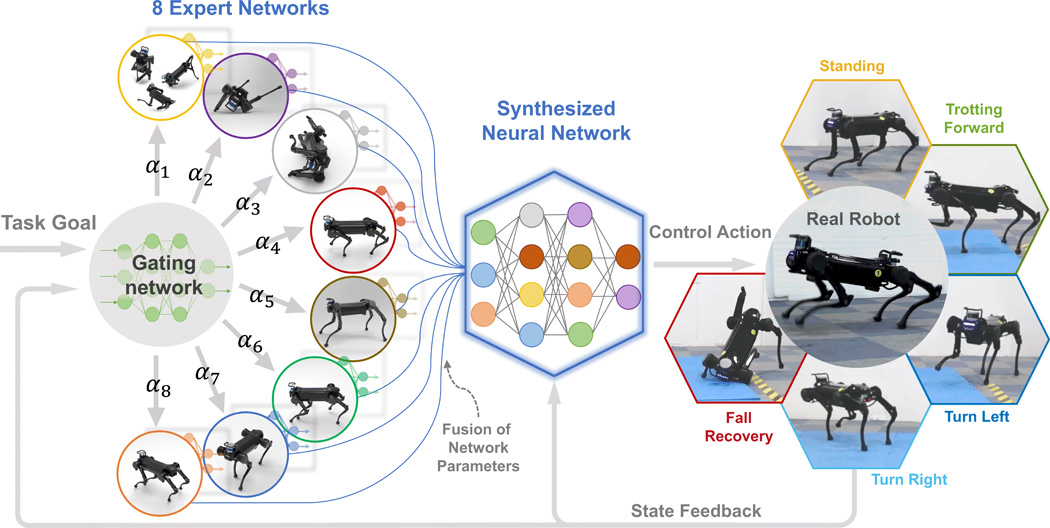
Zhibin Li, robotista dell’Università di Edimburgo e autore di un recente articolo sulla rivista Science Robotics che descrive il funzionamento di Jueying, insieme al team di ricerca, ha innanzitutto addestrato il software a guidare una versione virtuale del cane robot. Come? Mediante lo sviluppo di un’architettura di apprendimento con otto “esperti” algoritmici con lo scopo di aiutare il cane robot a mettere in atto ed imparare comportamenti complessi. Per ognuno di questi, è stata utilizzata una rete neurale profonda, specializzata in una particolare tipologia di abilità. Al robot sono poi state fornite delle “ricompense digitali” in caso di successo o, viceversa, dei “demeriti digitali” in caso di insuccesso. In questo modo, ognuno degli “esperti” ha acquisito padronanza su un’esperienza.
Grazie all’Intelligenza Artificiale, il robot simulato ha così potuto procedere per tentativi ed errori, sino ad imparare dall’esperienza, a differenza dei robot tradizionali in cui ogni possibilità, ambiente, configurazione è codificata meticolosamente, riga per riga. Non c’è modo di prevedere totalmente il caos, non è possibile codificare ogni imprevisto. Al contrario con l’AI, Jueying è in grado di resistere all’imprevisto.
Come si è detto, al contrario del metodo tradizionale, questo approccio consente di imparare compiendo un’azione centinaia di migliaia di volte o anche milioni di volte, se necessario. Quel che risulta fondamentale è il coordinamento e la collaborazione tra gli otto esperti algoritmici: i ricercatori li hanno infatti combinati in una rete globale in modo da farli agire (e reagire) allo stesso modo in cui una squadra si muove grazie al suo allenatore/capitano. (Nel video qui sopra, gli 8 esperti sono rappresentati dalle 8 barre verticali colorate). Camminare su una superficie ricoperta di pietre senza brutte distorsioni alle caviglie, correre su una superficie scivolosa: se il cane robot dovesse perdere l’equilibrio, tutti gli otto esperti, agiscono per ripristinare l’equilibrio, per farlo reagire, per farlo proseguire, ecc. E tutti questi apprendimenti, possono poi essere trasferiti dal robot virtuale al robot fisico.
Avremo così macchine più intelligenti, in grado di combinare abilità flessibili e adattive e di gestire una varietà di compiti mai visti prima.
Zhibin Li
Fonte:
Chuanyu Yang, Kay Yuan, Qiuguo Zhu, Wanming Yu, Zhibin Li (2020) Multi-expert learning of adaptive leggend locomotion, Science Robotics 9 Dec 2020, Vol. 5, Issue 49, eabb2174, DOI: 10:1126/scirobotics.abb2174